内存分配
学会管理Vulkan中的设备内存是非常重要。
Khronos 关于 Vulkan 内存管理的两场演讲是很好的学习资源:蒙特利尔 Vulkan Dev Day(视频)和 2018 年 Vulkanised(视频)。
管理内存并不容易,开发人员也可以使用 Vulkan Memory Allocator 开源库。
二次分配
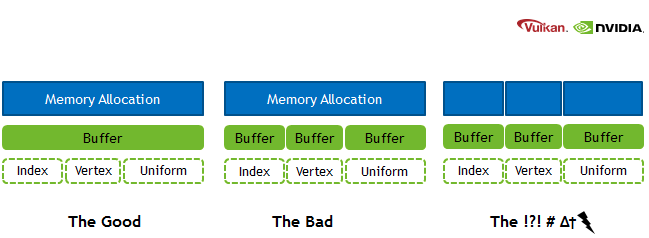
在 Vulkan 中,二次分配是一种优秀的做法。有一个 maxMemoryAllocationCount属性,它限制了应用程序可以同时使用的分配数量。OS/驱动程序级别的内存分配和释放可能非常慢,这也是使��用二次分配的另一个原因。Vulkan 应用应先创建一个大的分配区域,然后自行管理它们。
数据传输
VkPhysicalDeviceType 主要有两种类型的 GPU,离散和集成(也称为 UMA 统一内存架构),了解两者的区别对于性能来说非常重要。
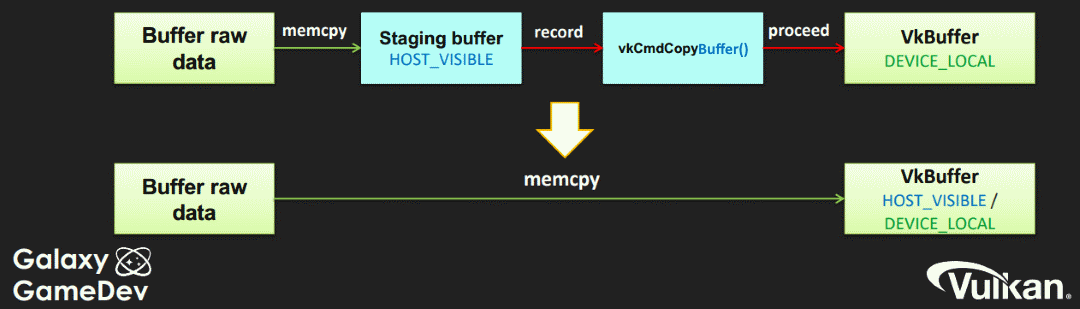
独立显卡设备有自己的专用内存,数据通过总线(例如 PCIe)进行传输,由于限制于传输数据的物理带宽速度,这通常是性能的瓶颈。一些物理设备会公开一个VK_QUEUE_TRANSFER_BIT队列,这是一个专用队列用来传输数据。通常的做法是创建一个暂存缓冲区,将主机数据复制到其中,然后再通过命令缓冲区指令以复制数据到设备内存。
UMA 系统的设备和主机之间共享内存,该内存使用VK_MEMORY_PROPERTY_DEVICE_LOCAL_BIT | VK_MEMORY_PROPERTY_HOST_VISIBLE_BIT组合。这样做的缺点是必须与 GPU 共享系统内存,可能会导致内存不足,优点是无需创建暂存缓冲区,因而传输开销大大降低。
延迟分配
在tile-based的架构�上(几乎所有的移动 GPU),内存类型LAZILY_ALLOCATED_BIT没有保存在实际的内存中。它用于保存tile内存中的附件,例如subpasses之间的G-buffer、深度缓冲区或多采样图像,这节省了将图像写回内存的带宽开销。可以在 Khronos 的 Render Pass 和 Subpass 教程中阅读更详细的内容。